
AI出图到底哪家更准确一点,以及在工作中能否快速用ai+实时演示的工具来实现效果制作。
AI生UI图哪家更准确
其实我们都知道,目前ai做UI图还是无法有效的应用去生产,但是我们也能肉眼发现,ai在UI制作上的一些进化之处。从最开始通过提示词生产几张歪瓜裂枣,到后来的可以进行局部调整控制以及生成的界面越来越真实化。那么目前这么多ai产品里面,有哪些产品生产UI界面会更加符合我们的要求以及准确性呢?
这次我让豆包、即梦4.0、nanobanana、妙多、通义、google stitch 3.0分别来参加这次比赛,大家来看看谁更厉害。
在生图之前呢有一件事是最关键的,那就是提示词怎么写?为了准确的生成我们要的界面,那么提示词的颗粒度一定要把控合理,不然就像我上一篇那一大串吊炸天的提示词让ai也直接崩溃了,所以提示词并不是写的越细越好,当然也不能一句话概括。那么到底怎么写提示词比较好呢?我们依然让ai来告诉我们。
下面我给几个ai分别提供了同一张图片,让他们以此来生成提示词。以下分别是即梦、豆包、google stitch以及nanobanana,我们能发现他们生成提示词都有同一个逻辑。
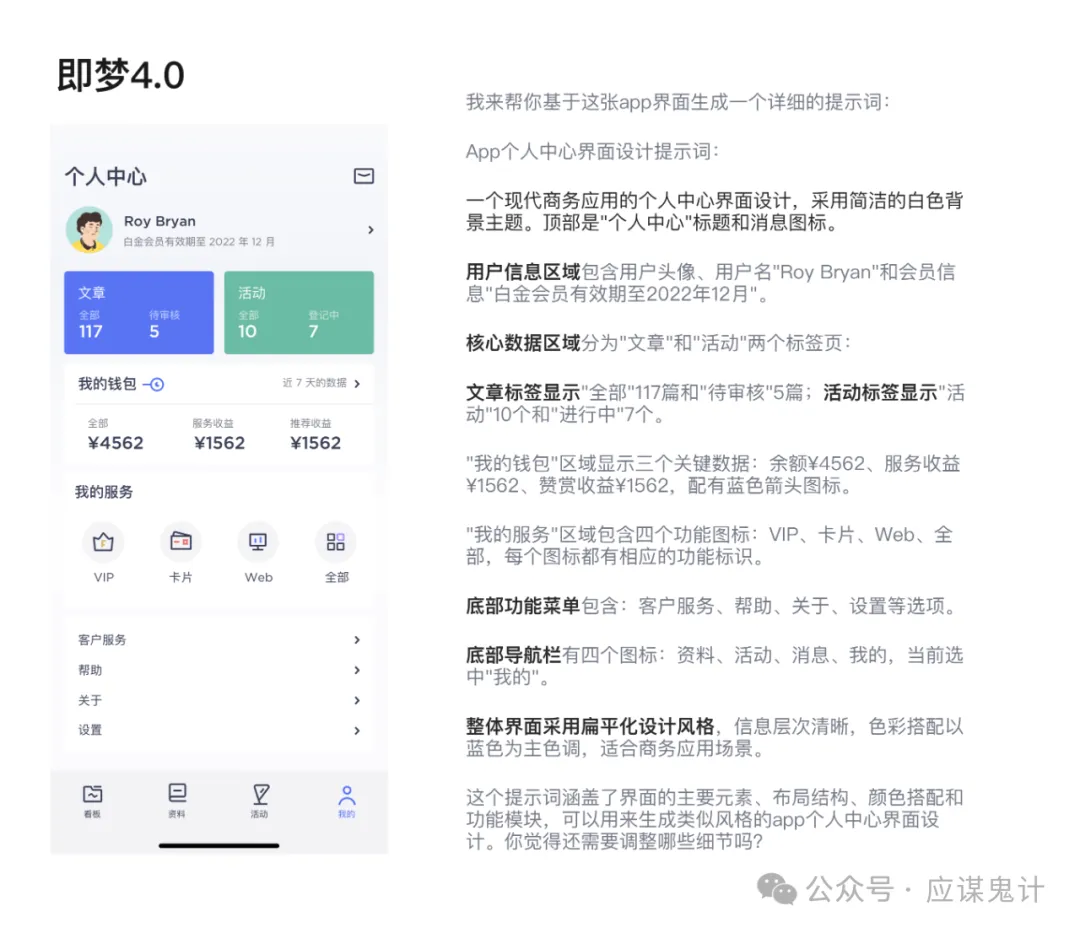
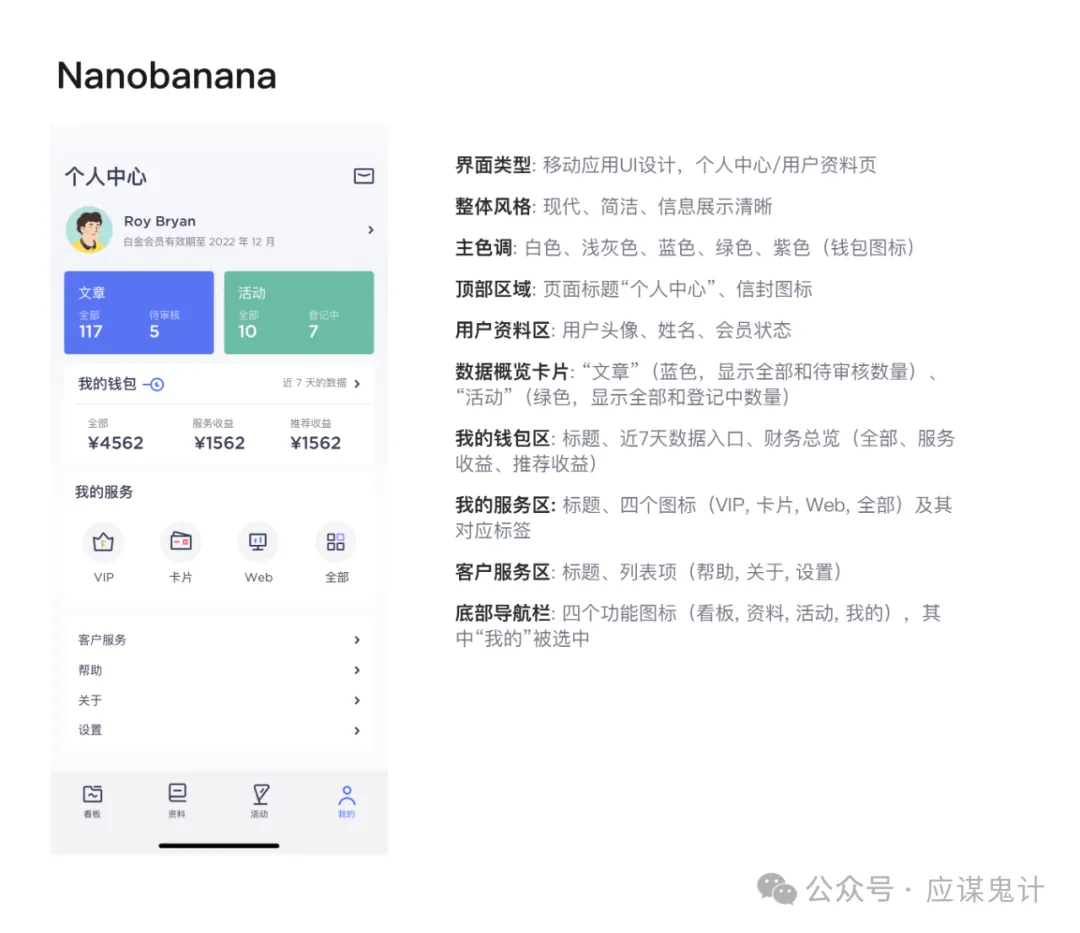
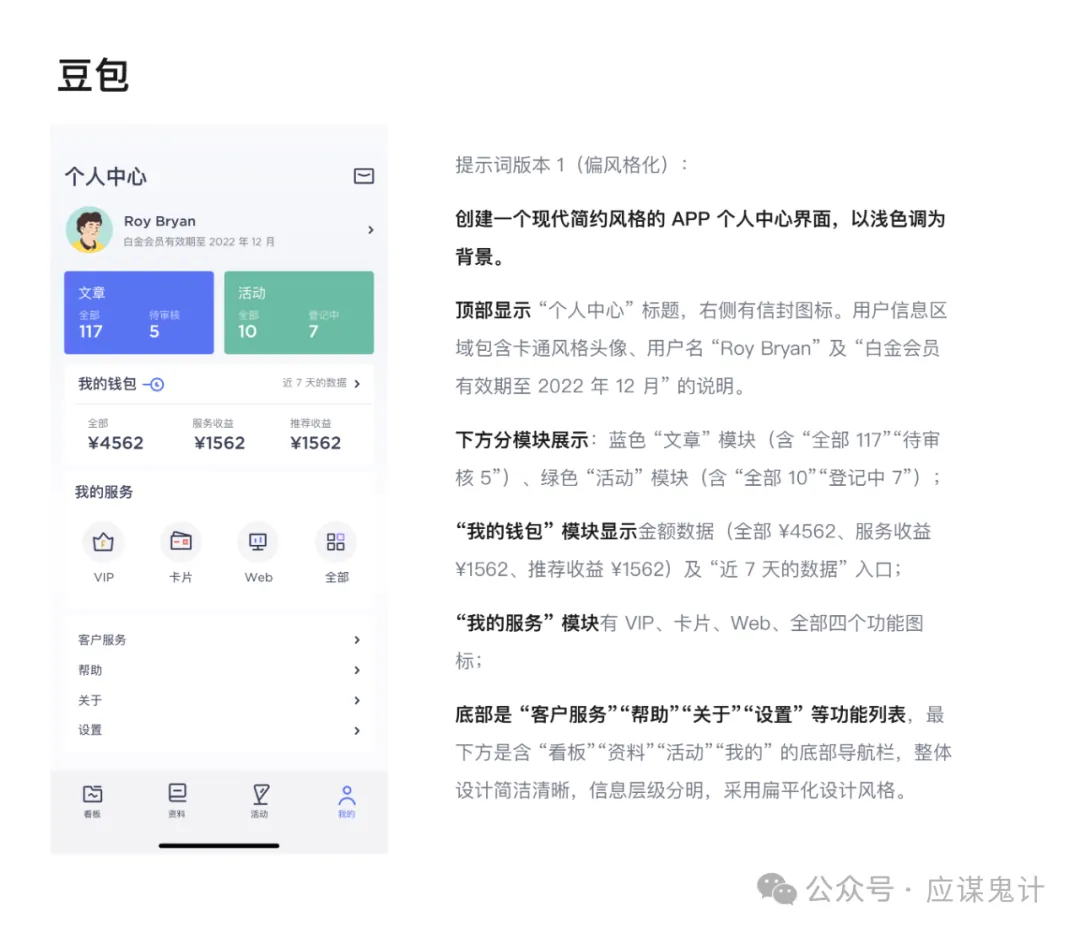
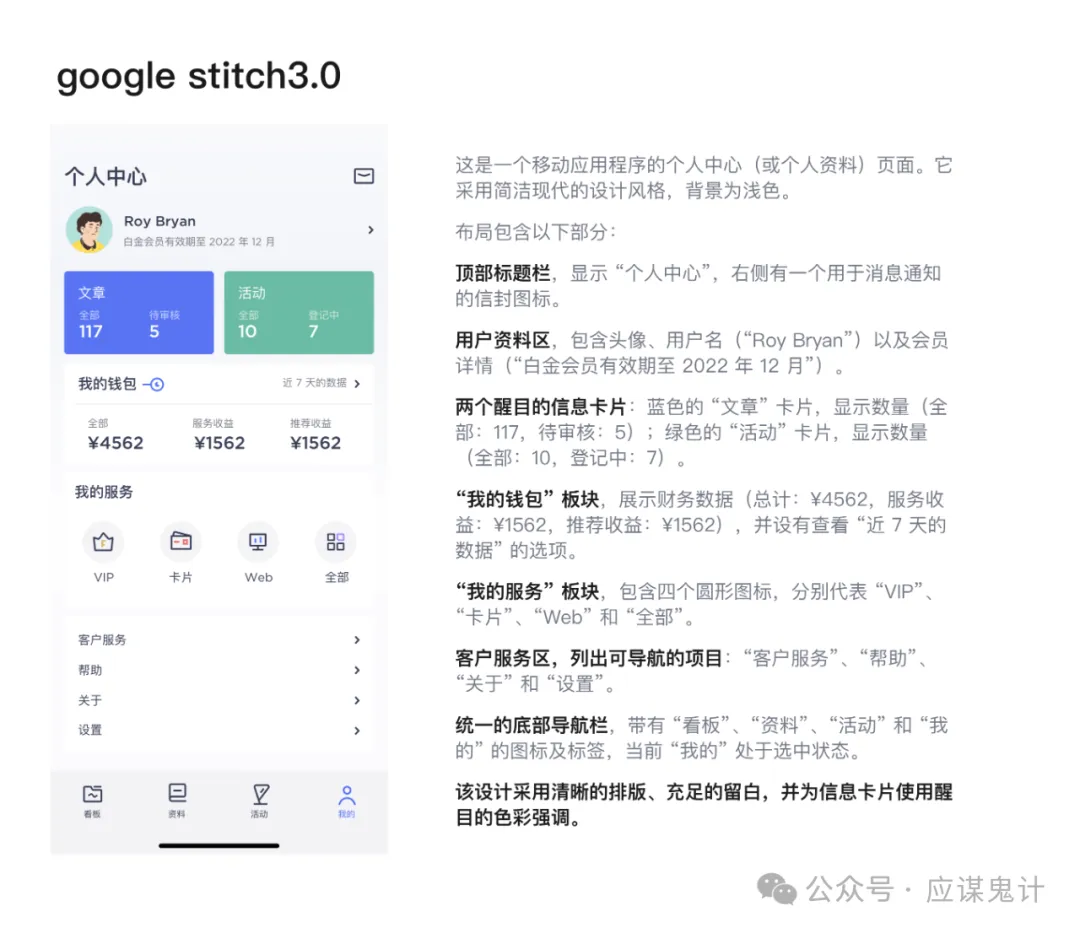
那就是分模块和分维度描述,先明确界面的内容主题,其次从上到下去针对不同模块的区域进行“大致”描述,没有精确到尺寸、距离等很细节的参数,基本上都只是在描述模块内容。最后或者在描述开始时,对整体风格进行总结描述,包括色彩、卡片风格等。
那么接下来我们依次让上面的参赛选手来分别尝试根据这四套提示词来生成UI图像。豆包和即梦用的是同一个大模型,那么我们就合并在一起。
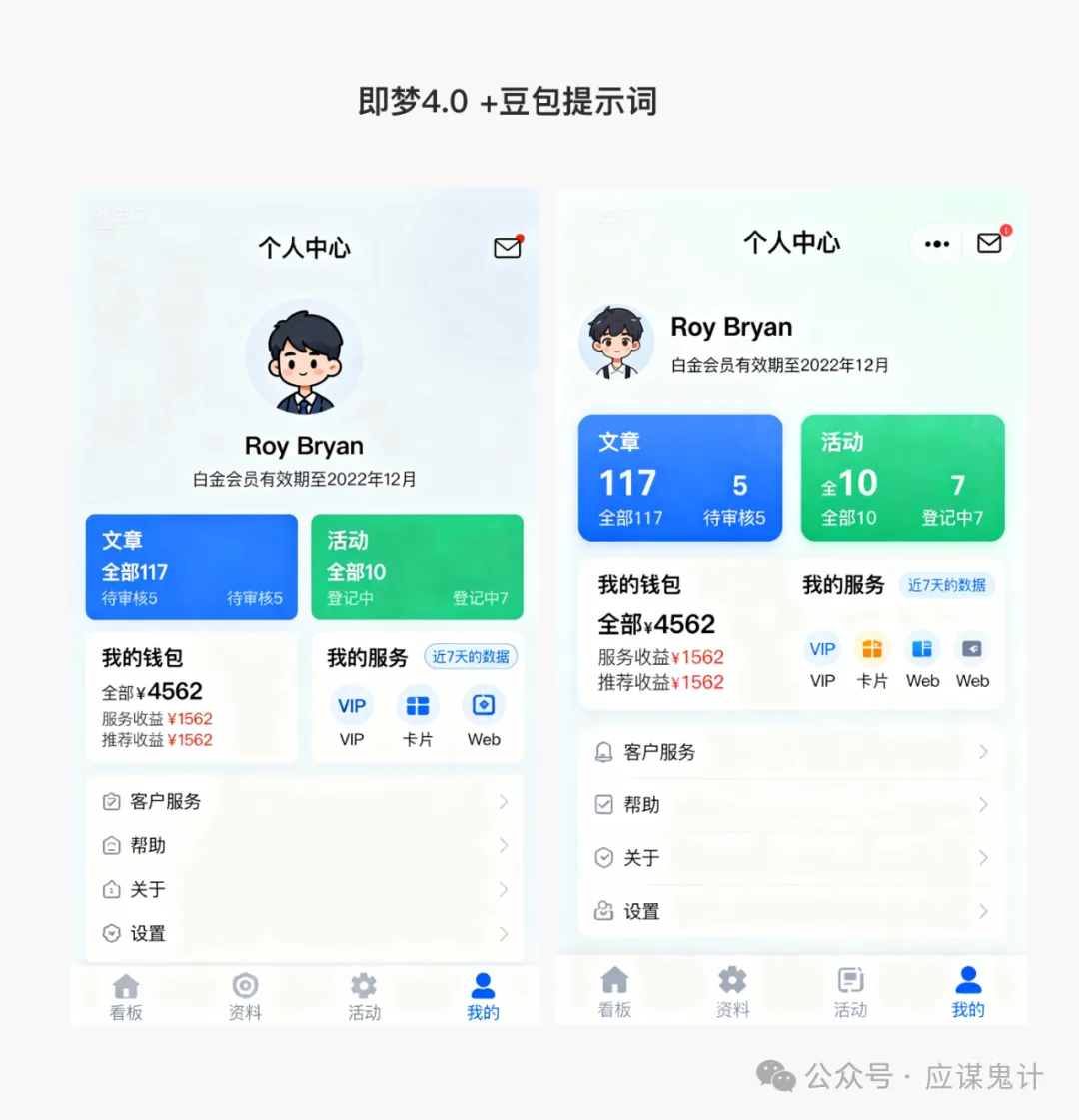
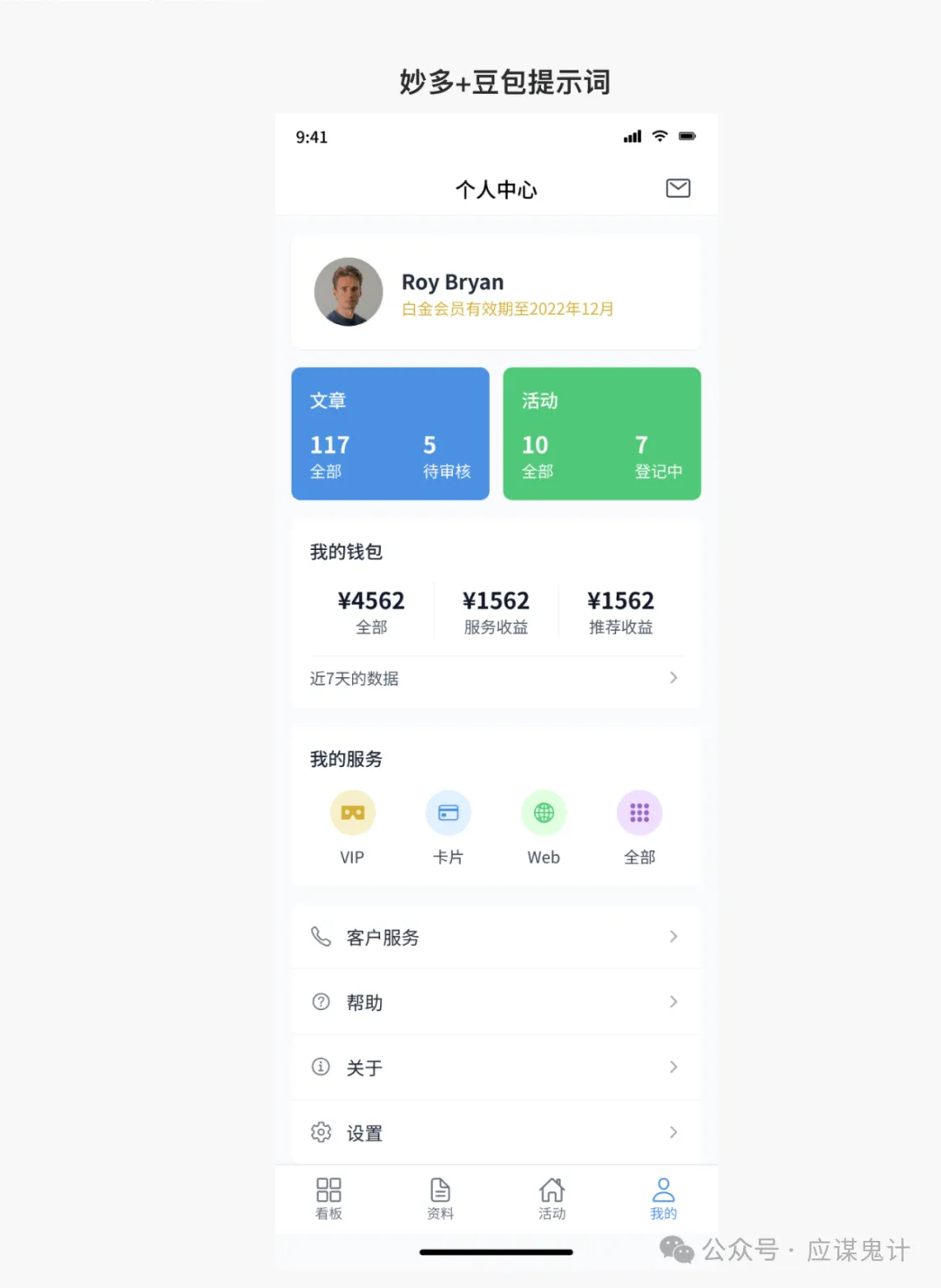
首先是豆包/即梦选手
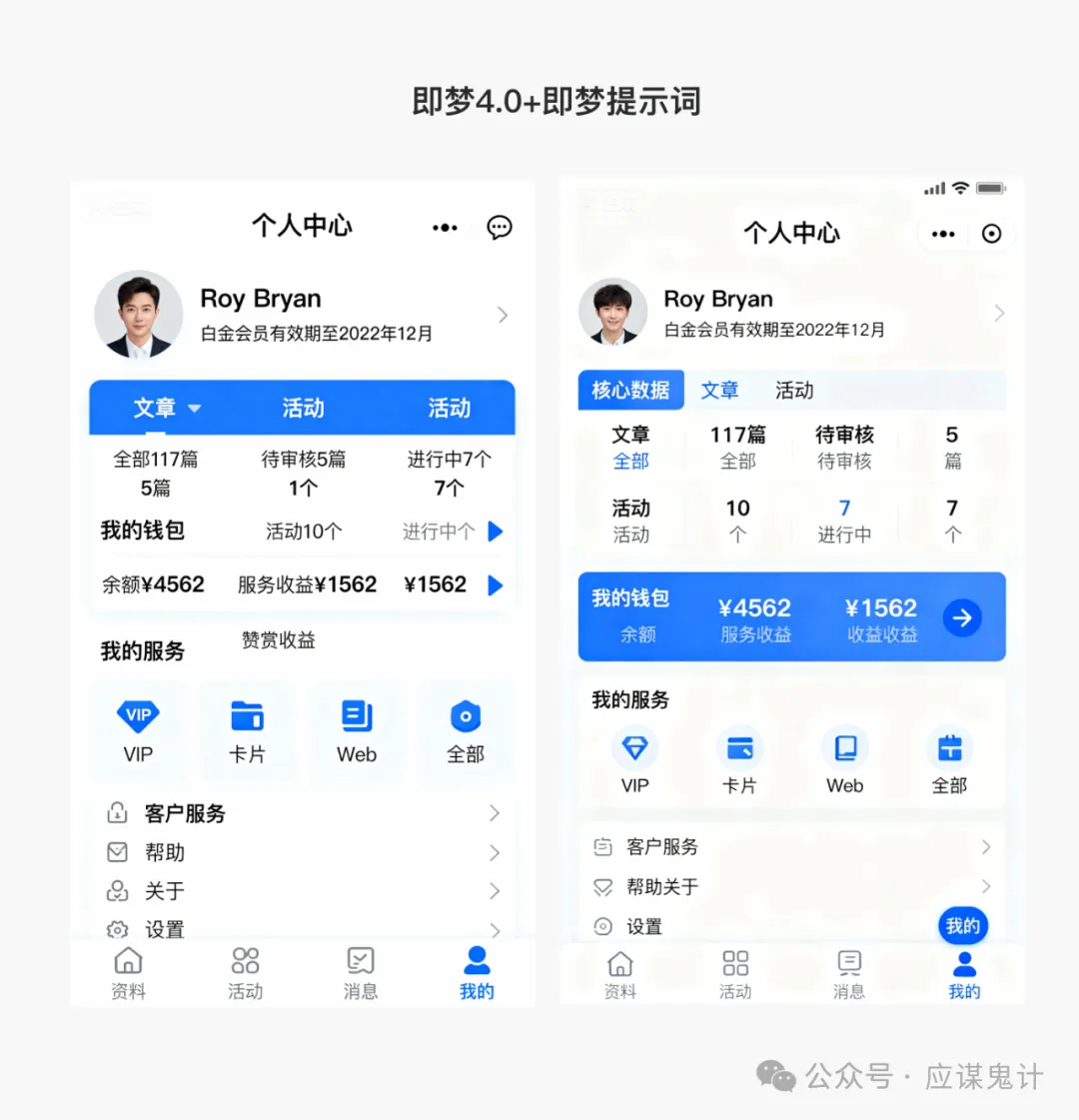
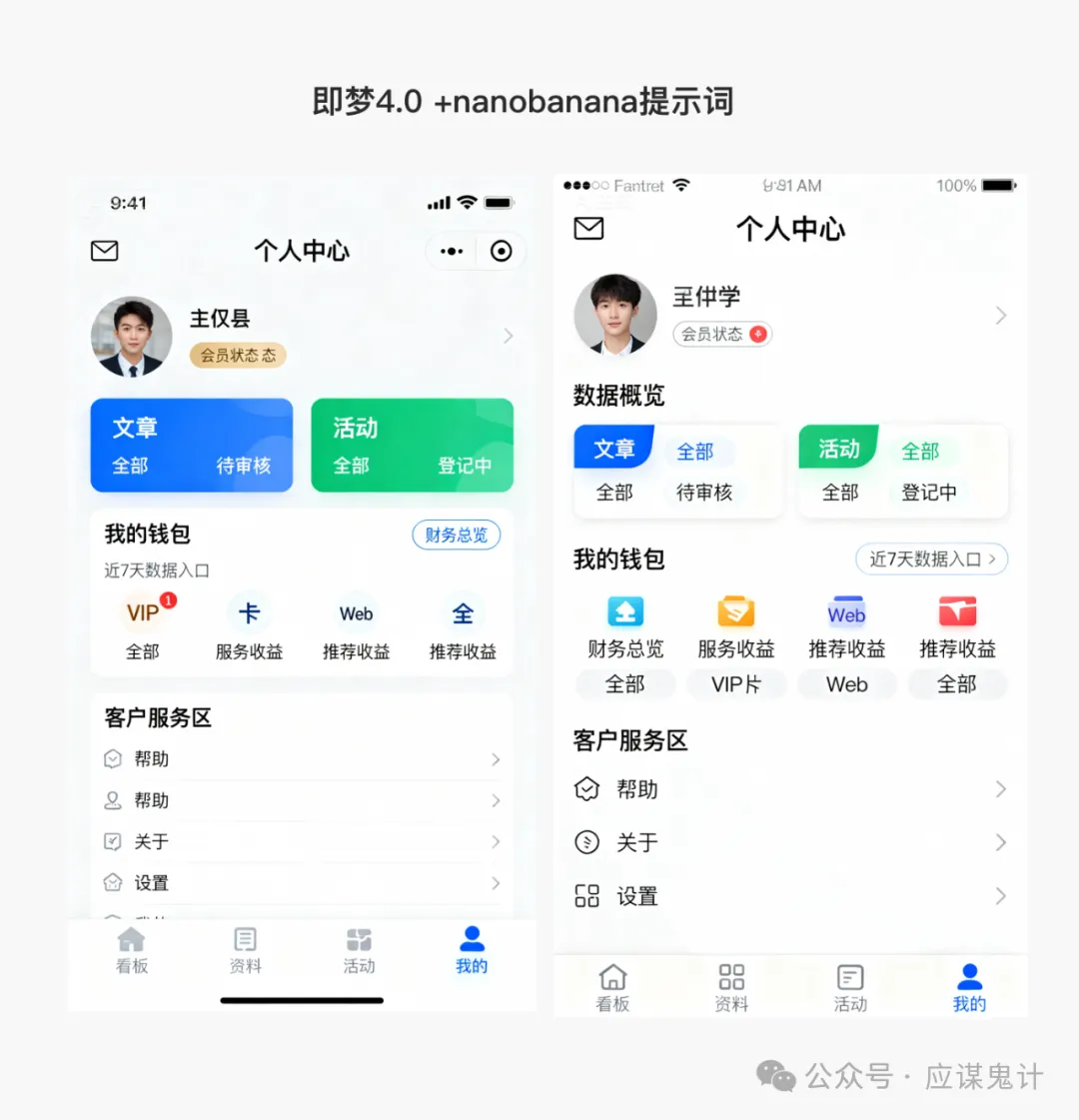
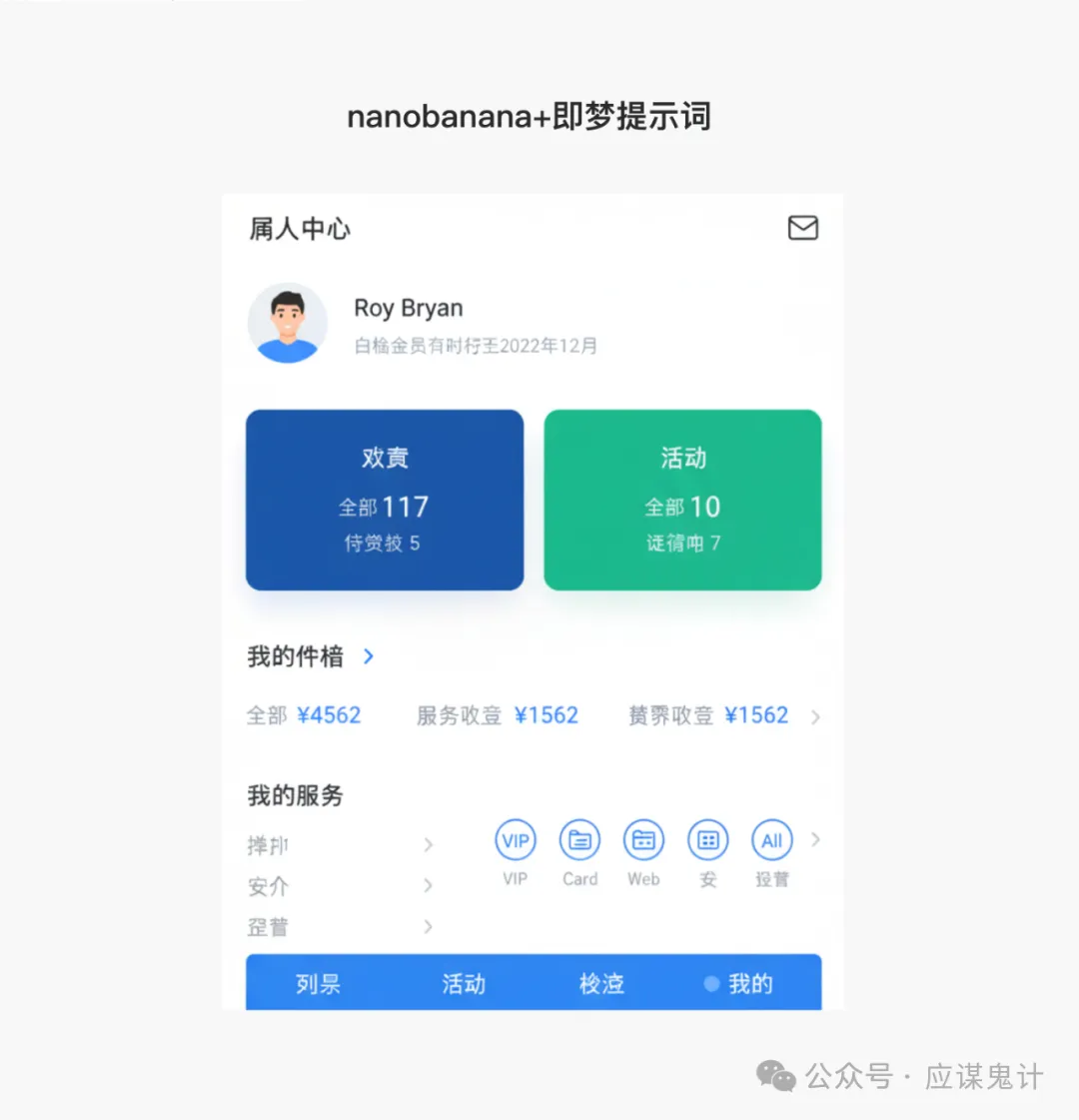
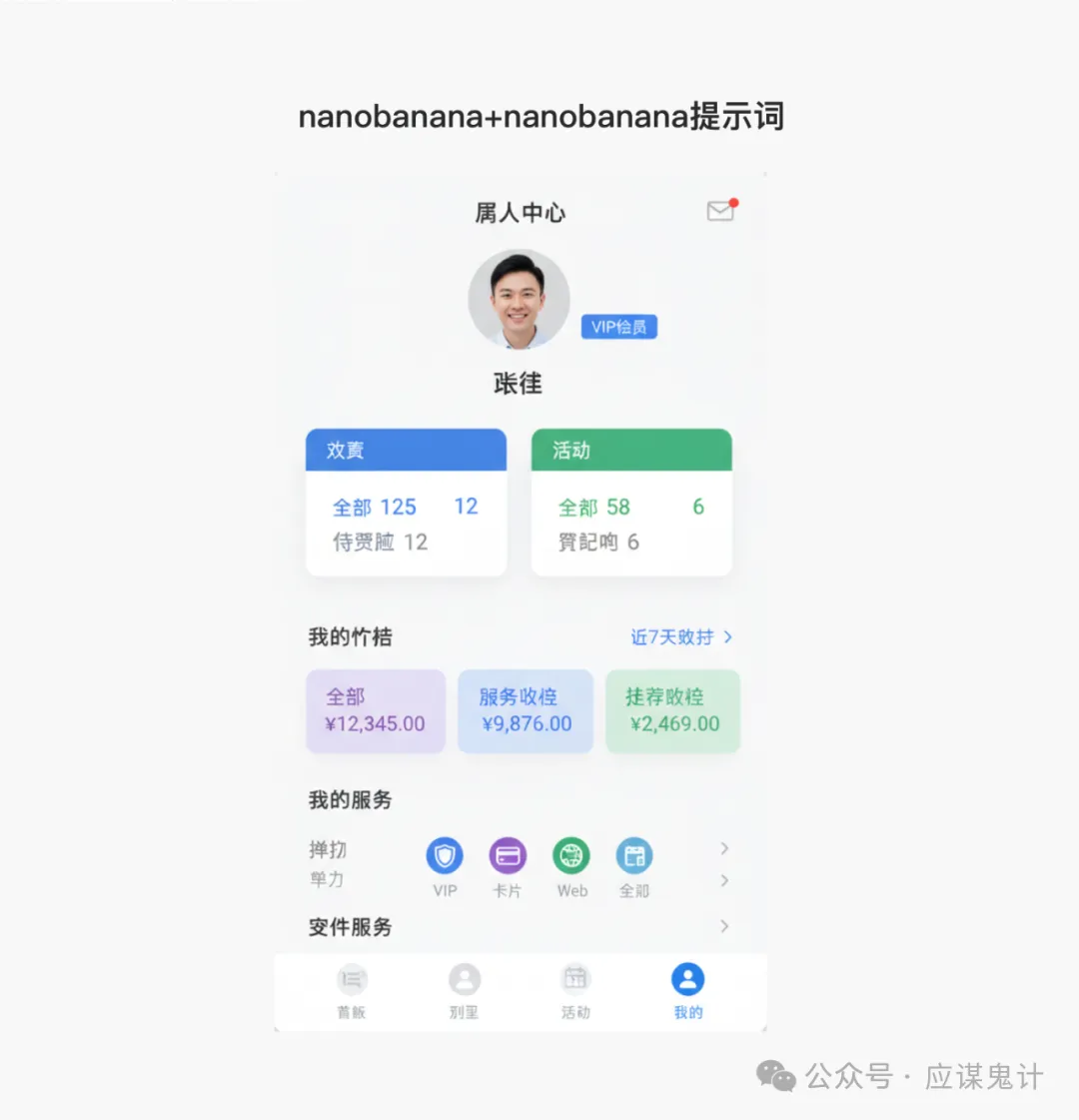
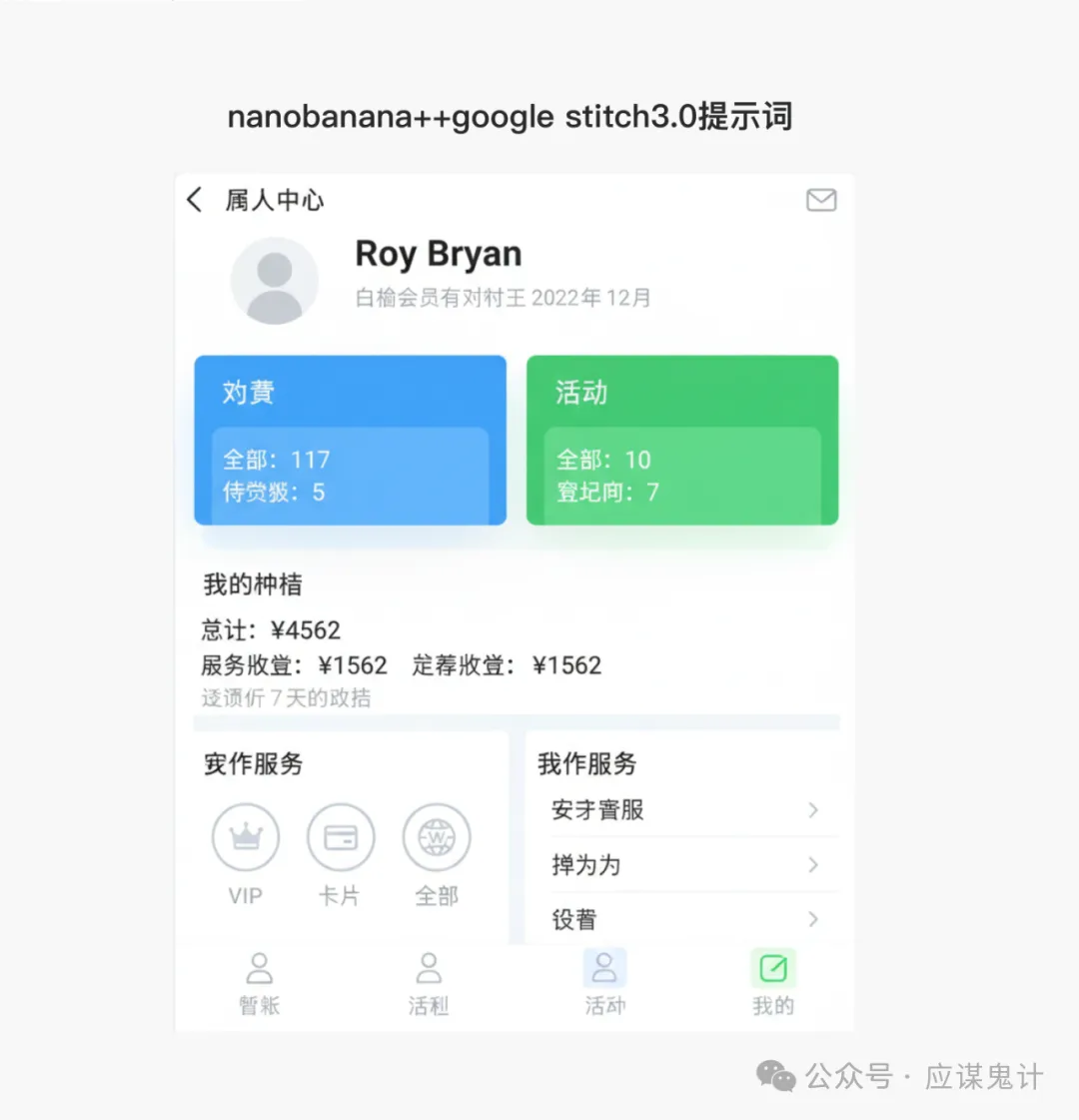
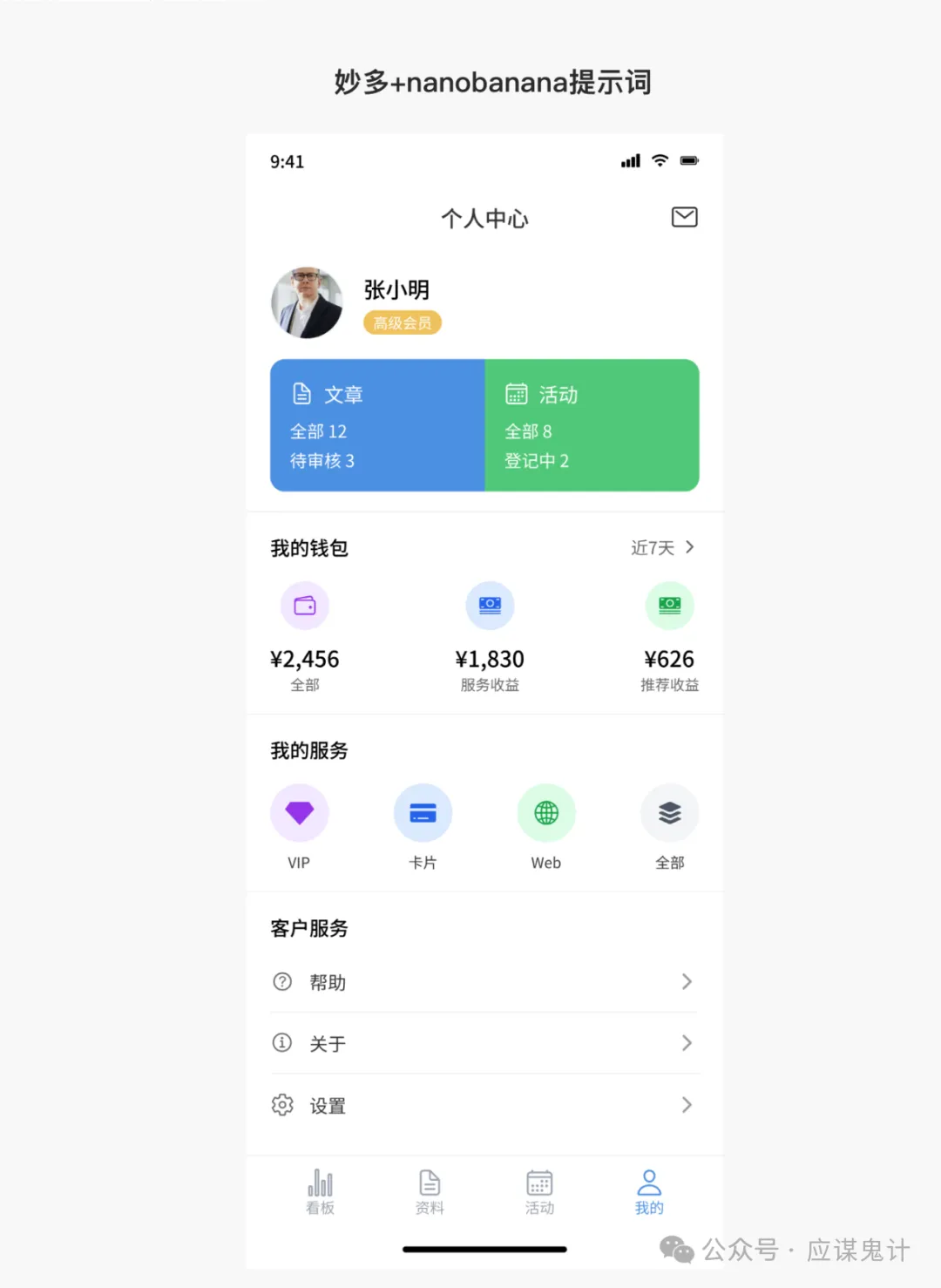
然后是香蕉选手
接下来是通义
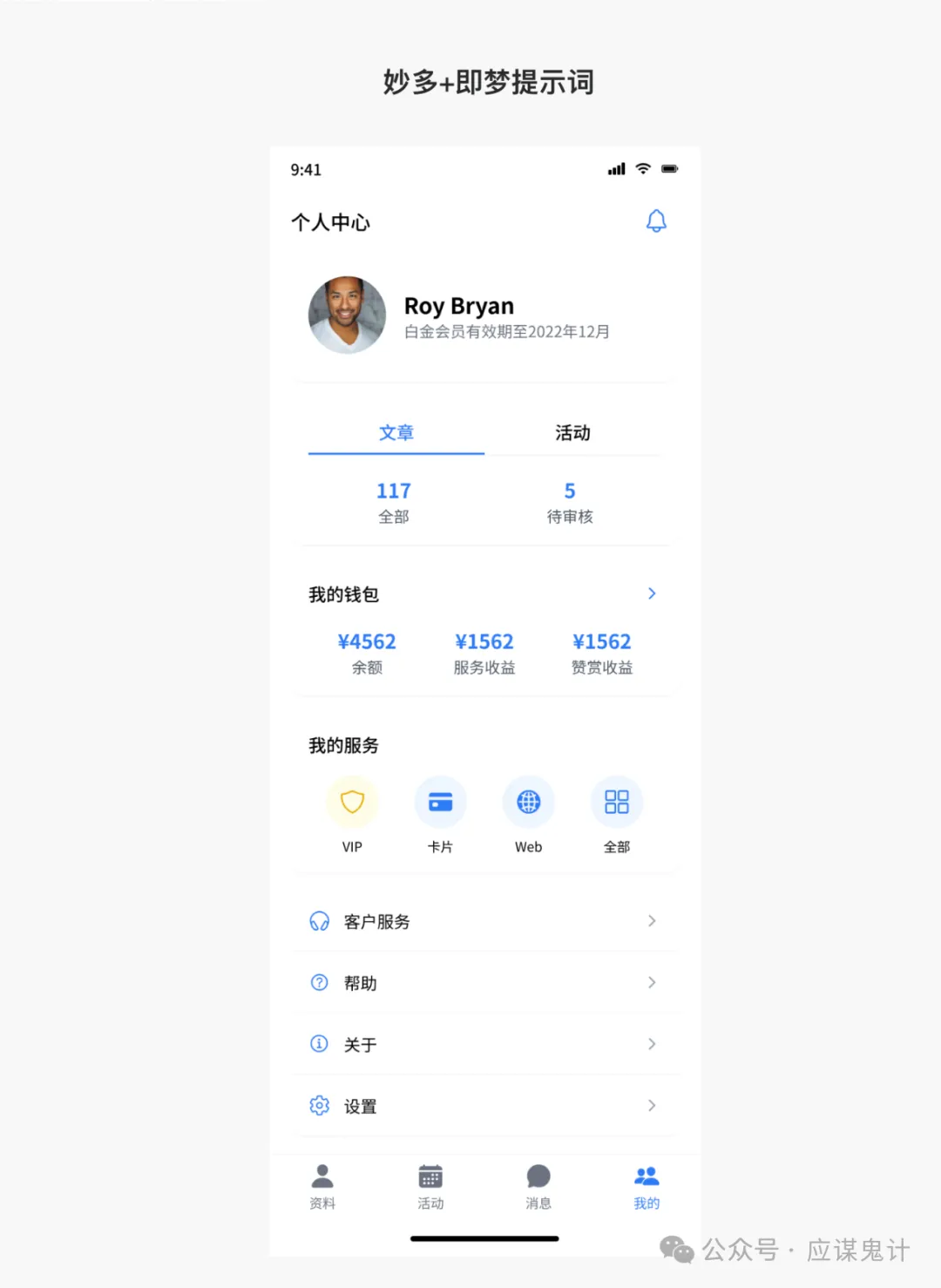
然后是妙多选手
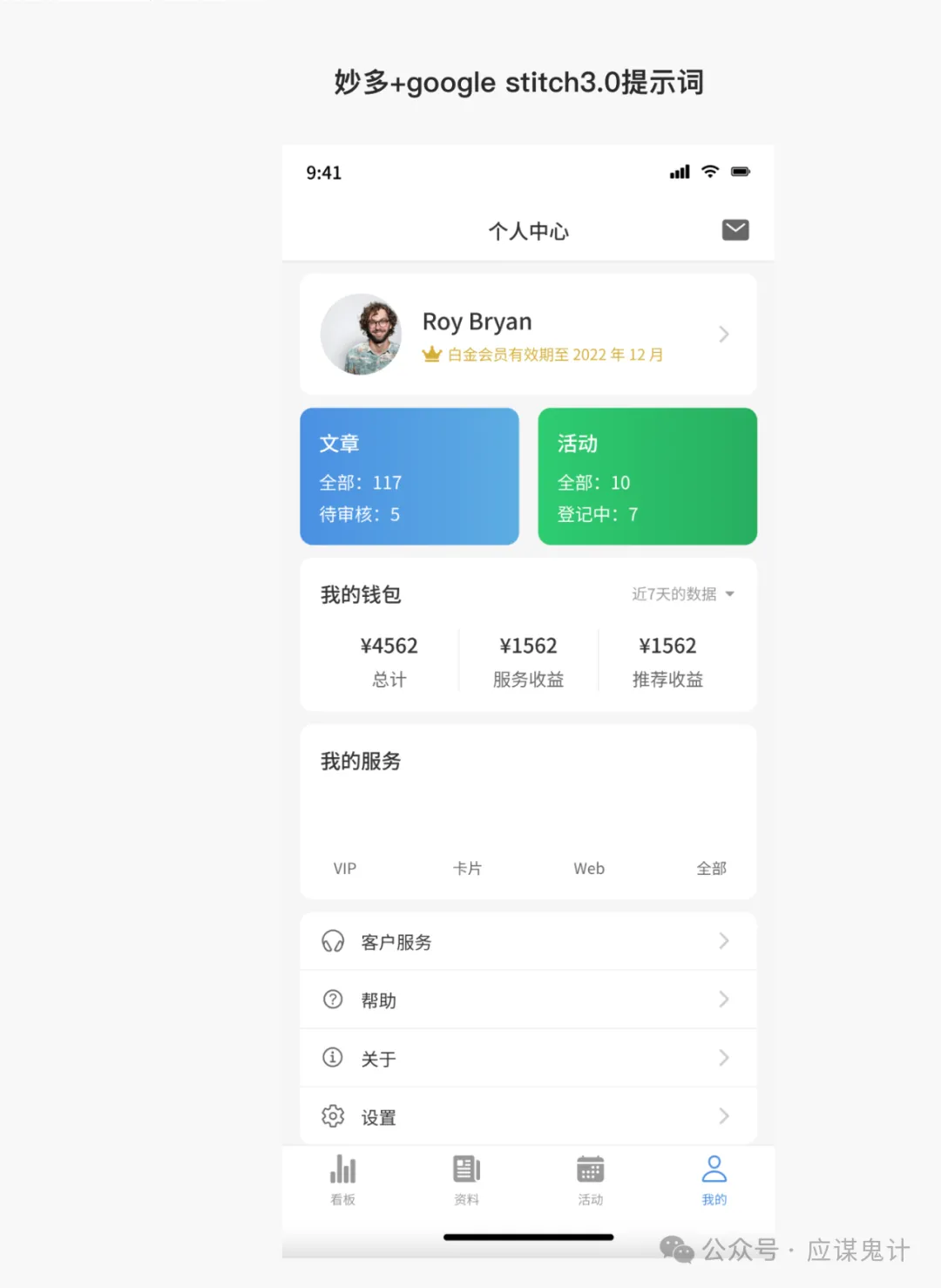
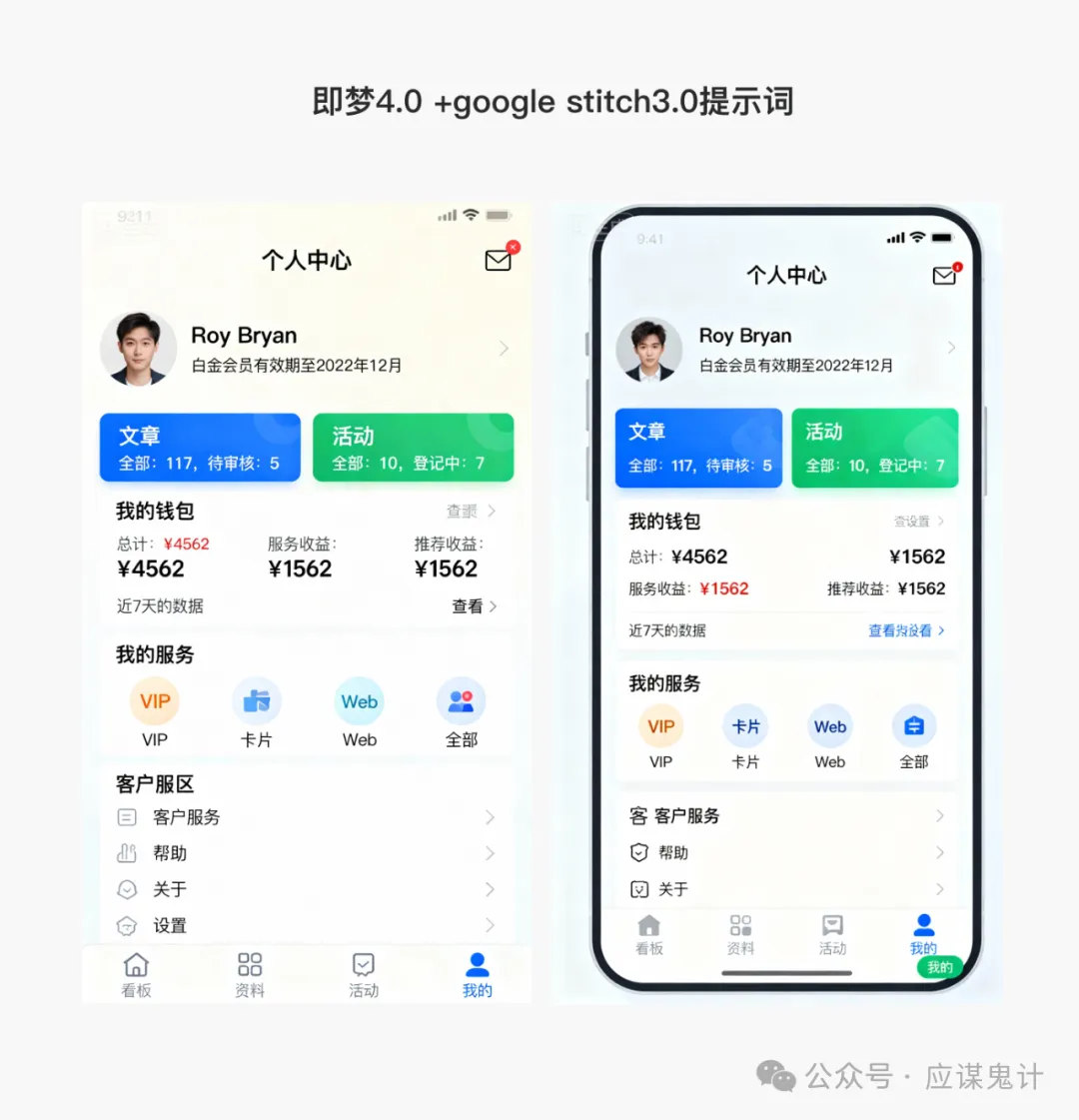
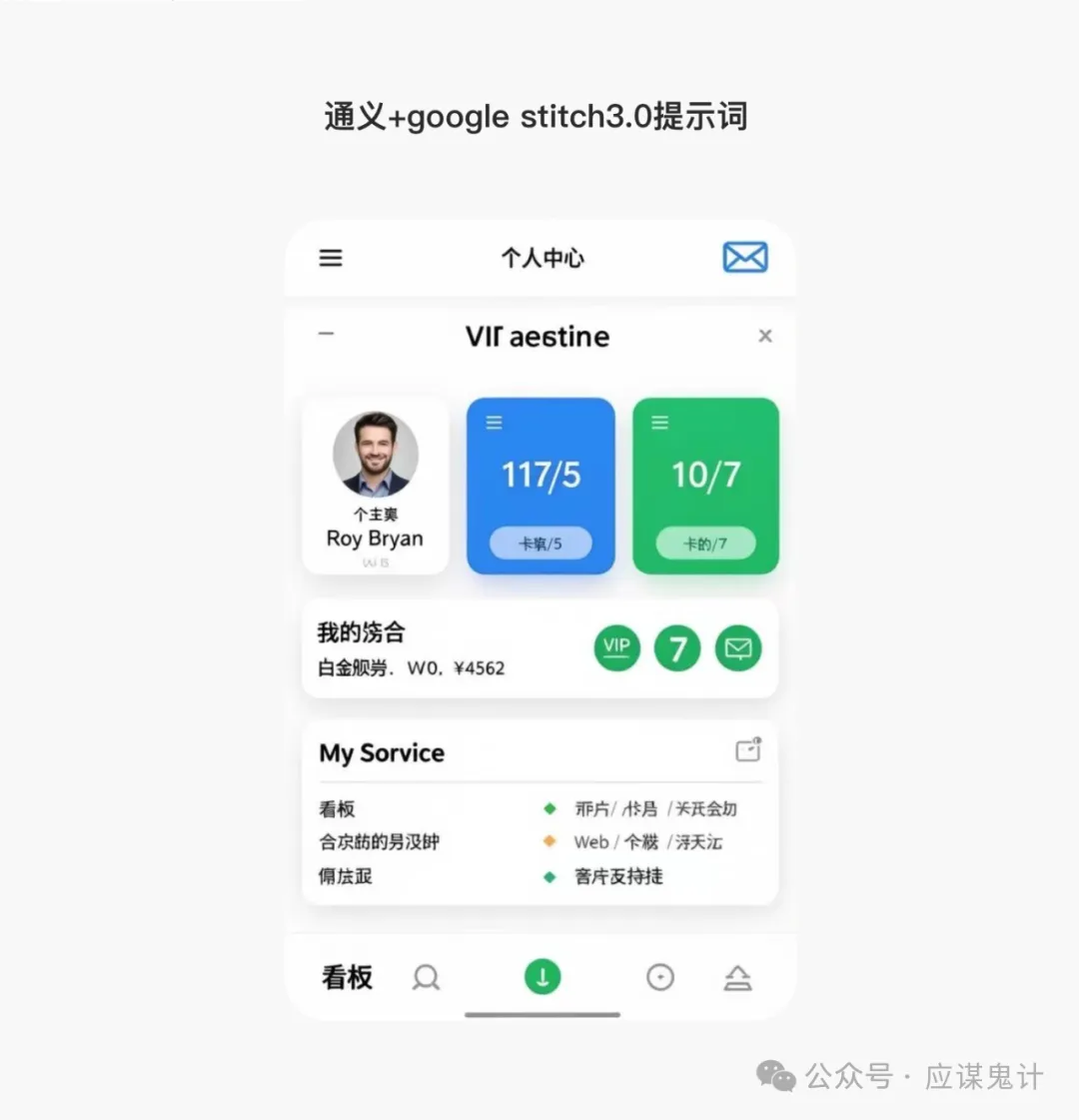
最后是google stitch
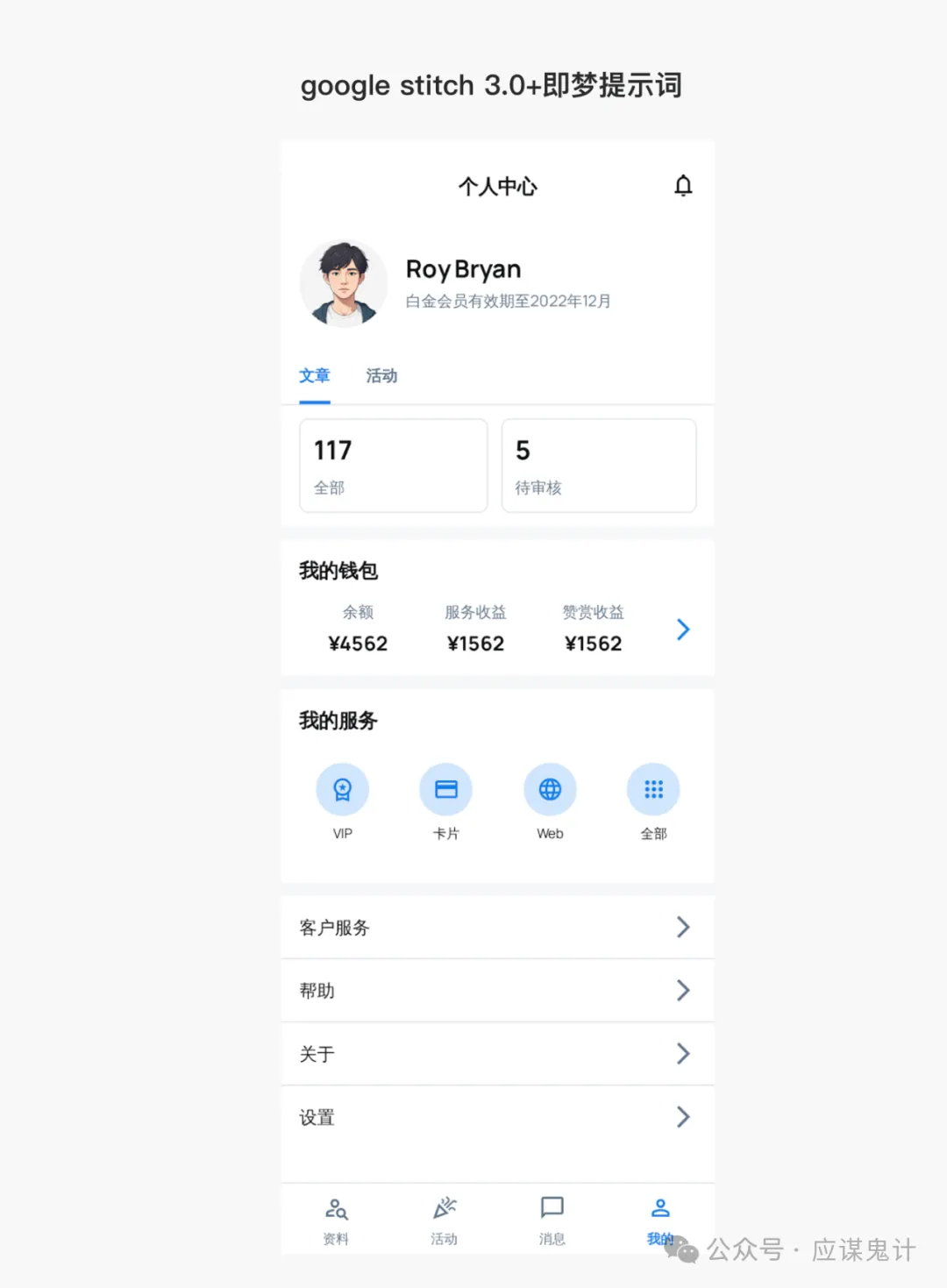
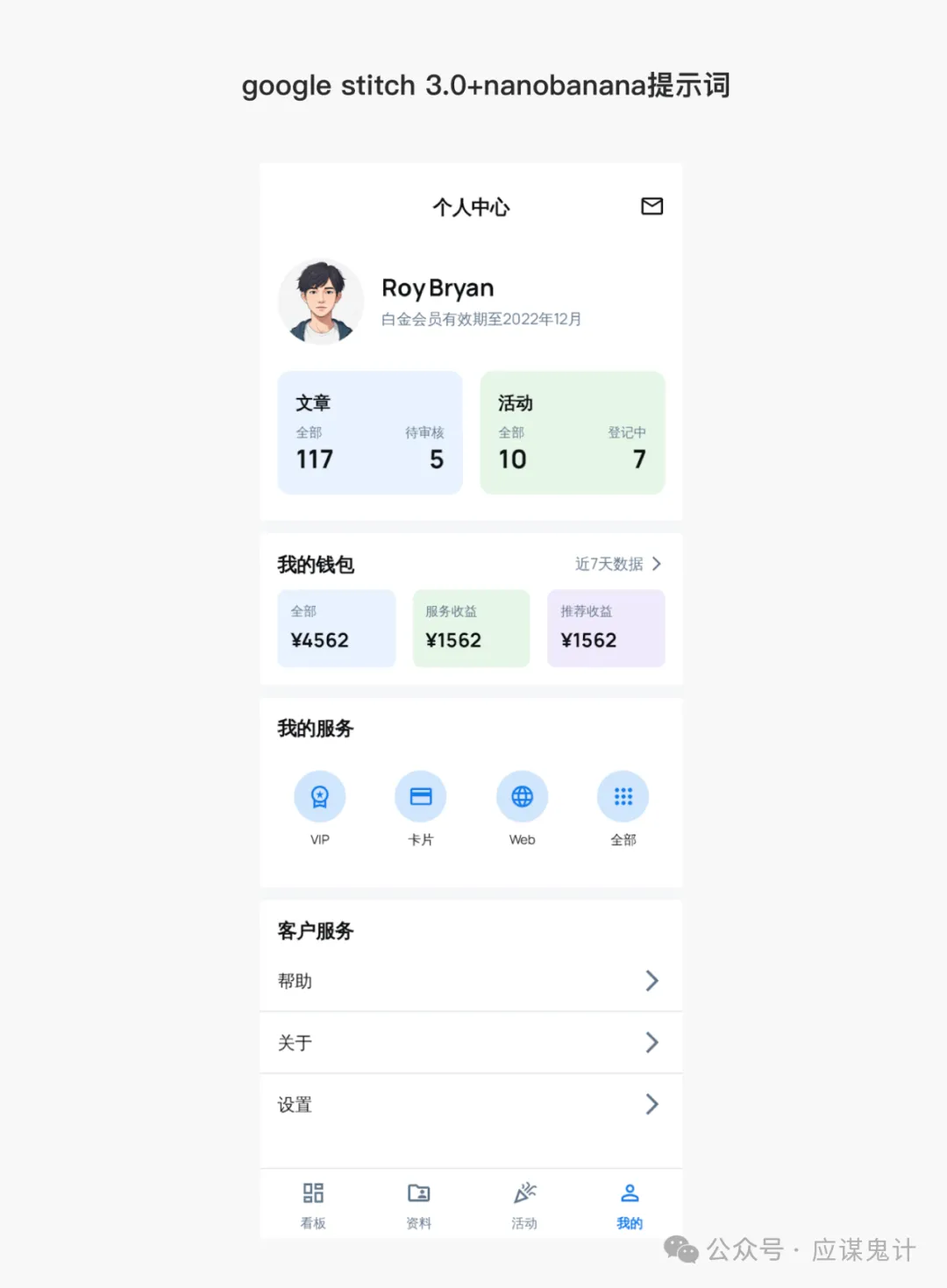
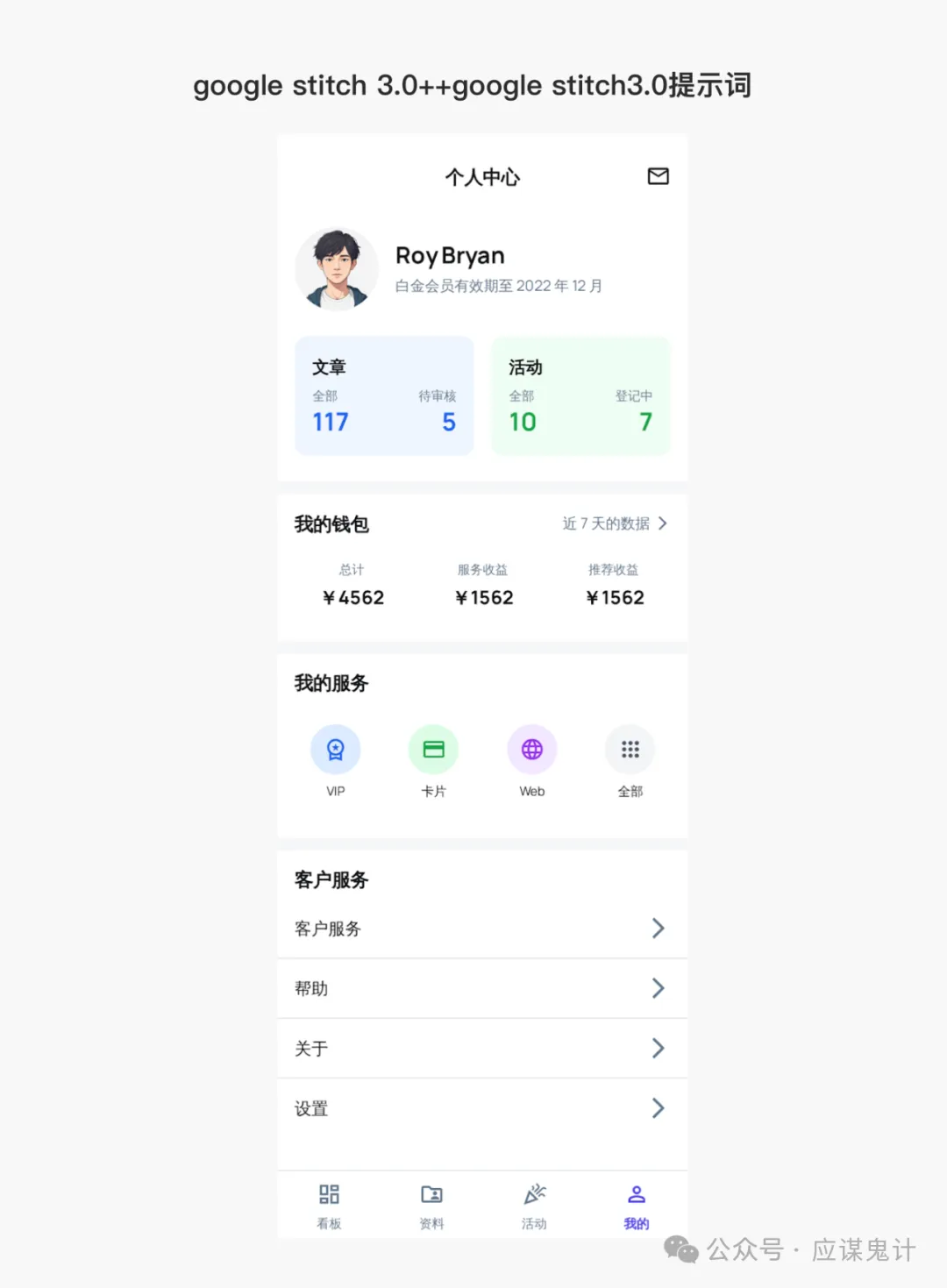
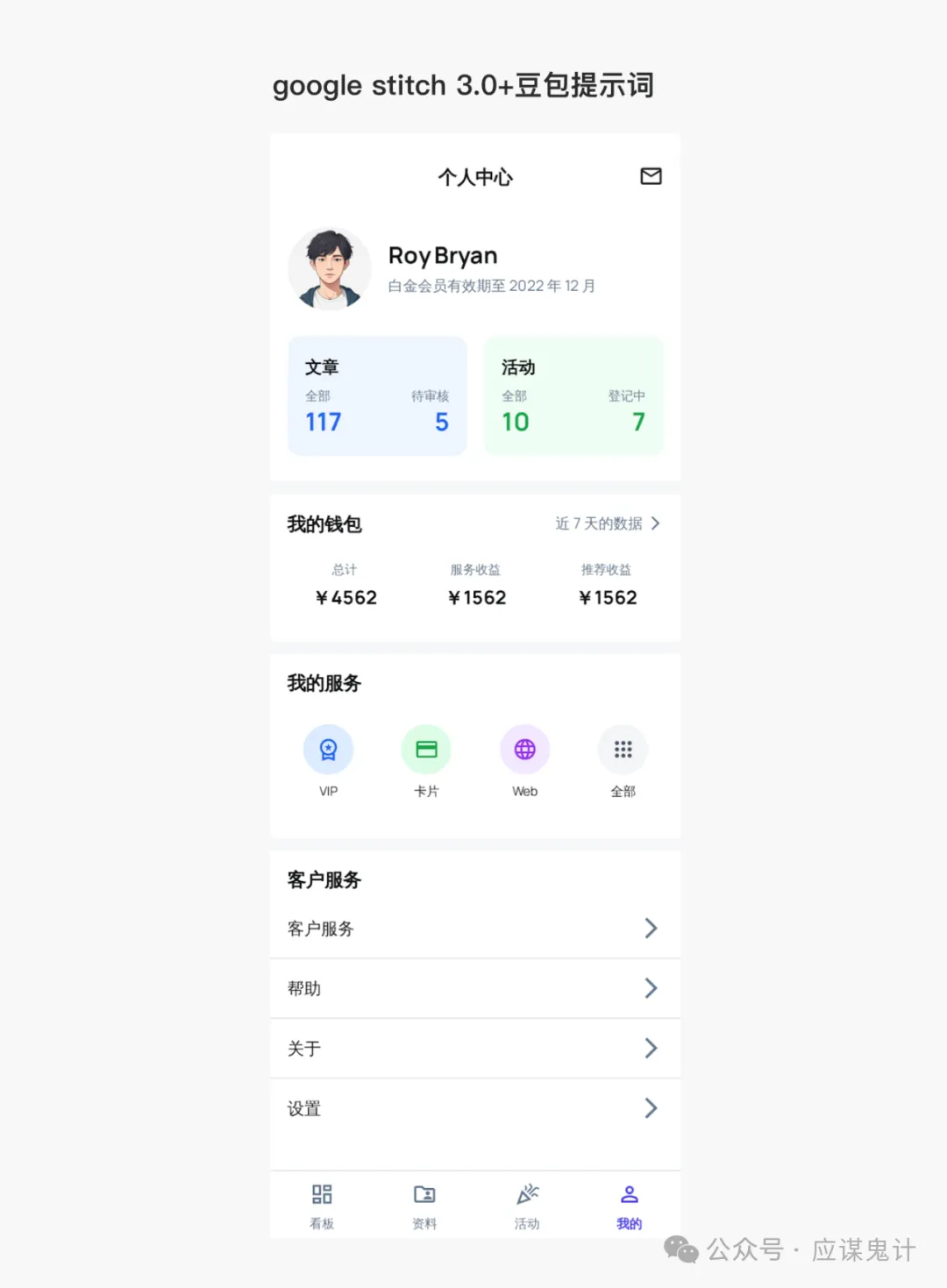
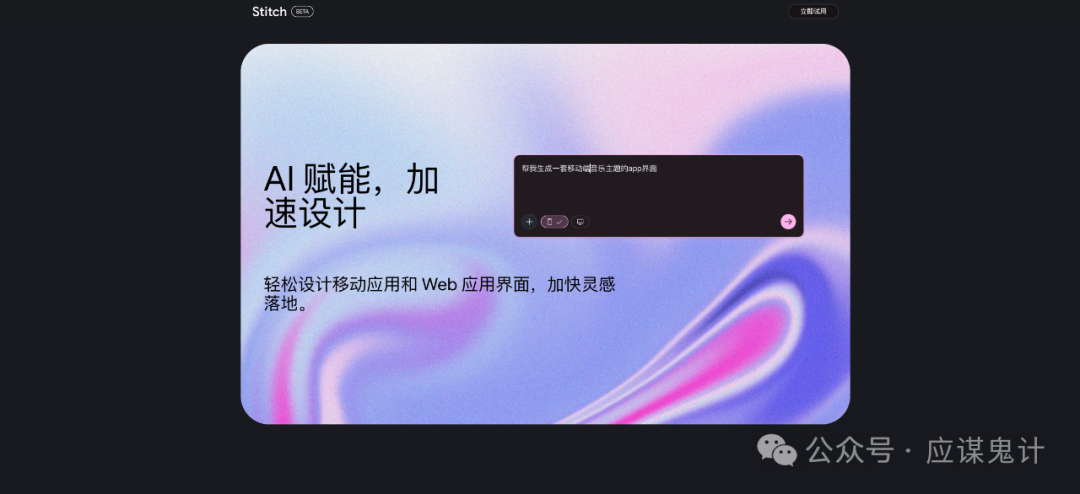
那一番比较下来,我们能明显发现google stitch和妙多生成UI图是相对来说OK的。在提示词方面用google stitch和豆包的提示词的格式生成的图会更好一点。所以大家目前如果要用ai玩UI的话,用用stitch就可以了,毕竟人家是免费的,效果也挺好,关键是可扩展和ai的控图效果也不错,还能出代码和交互逻辑。
不过话说回来,用ai来出UI,这件事情,就不太靠谱。因为UI的价值不是在画图上,虽然画图需要花费一定的时间,但是我觉得目前为止已经到达了一个平衡点。并且他不像创意图像那样靠抽象的想象去抽奖,这就好比你用ai生成了一个人物,你不会继续用ai去改这个人物手指上的指纹,但UI就是这样,你生成出来的图即便再好看,不符合整体的规范、没有业务背景和用户背景的条件限制,都是白搭,甚至还要精调。当然现在的ai模型越来越强大了,咱们也可以拭目以待。
评论(0)